The Primacy Bias in Deep Reinforcement Learning
本文最后更新于:2025年2月22日 下午
The Primacy Bias in Deep Reinforcement Learning
原文:The Primacy Bias in Deep Reinforcement Learning
深度强化学习存在一种普遍缺陷——倾向于依赖早期的交互,而忽略后来遇到的有用证据(现象背后就是模型可塑性的丧失)
文章将这种现象用描述为primacy bias(首因效应。来自认知科学。感觉翻译成先入为主效应更通俗易懂,后面都这么翻译)
文章通过实验展示了DRL中存在primacy bias;揭示了可能原因——heavy priming(过度启动);验证DRL算法设计加剧了这种偏见。
提出了resetting机制缓解问题。
实验验证resetting机制的有效性;分析resetting机制对学习动态特性的影响。
先入为主效应
The Primacy Bias in Deep RL: a tendency to overfit early experiences that damages the rest of the learning process.
对于早期数据的过度学习。
过度启动造成难以恢复的过拟合
实验设置:SAC + DMC。一个正常训练,回放率为1;另一个没看懂,见下面评论,总之加大了模型在已有数据上的训练强度。
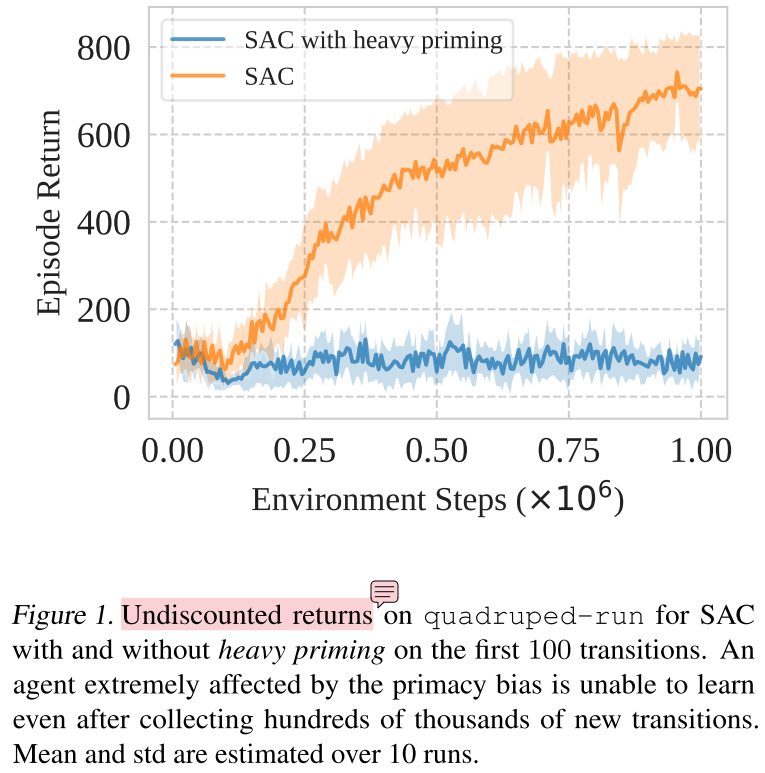
是每收集到100个数据,在这上面更新100000次梯度,然后重新收集100个数据,如此进行吗?
还是说收集100个数据,在这上面更新100000次梯度,然后正常训练?
过度启动的智能体事实上拥有足够的数据摆脱问题
实验设置:SAC + DMC。一个回放率设为9进行训练;另一个应该是回放率设为1进行训练(文中没提到),并使用前一个SAC智能体收集的数据作为其初始经验回放池。
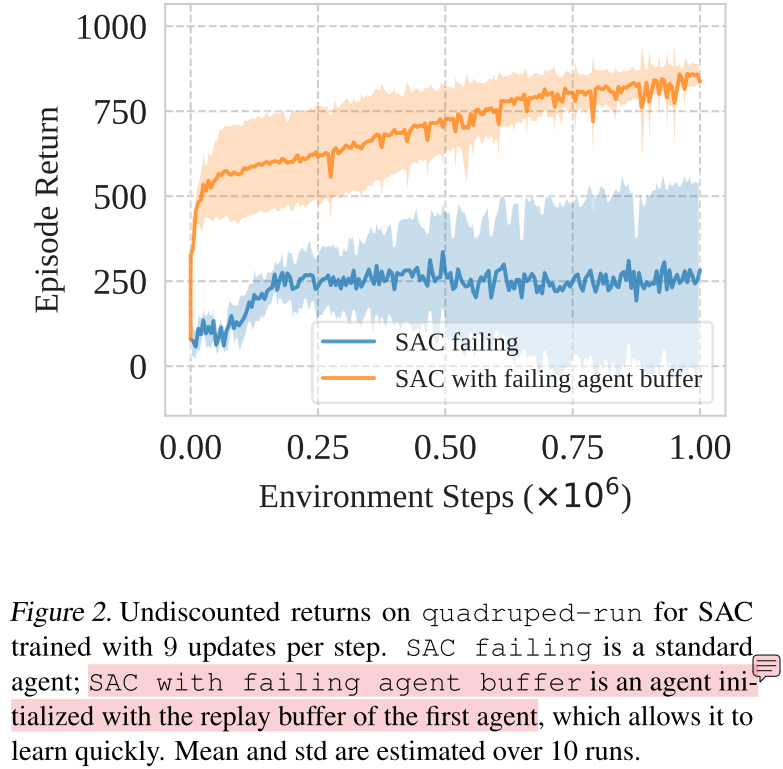
SAC with failing agent buffer这个实验设置还是没理解清楚,只在初始化时使用前一个agent的数据吗?还是说是离线强化学习?似乎只有后者才能说明过度启动的智能体拥有足够的数据。
实验结果表明:陷入primacy bias的智能体,与环境交互的场景的多样性是足够的。问题不在于数据的分布受限,而更像标签的可信度低(尤其是前期)以及标签的波动(图中蓝色曲线的方差)。
resetting机制
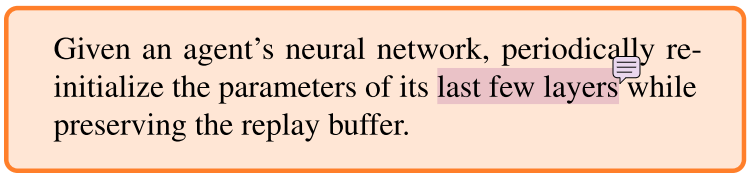
周期性初始化最后几层的参数,保持replay buffer的具体实现方案根据任务定制。
实验
- 验证resetting机制的有效性;
- 分析resetting机制对学习动态特性的影响;
- replay ratio和n-step target对resetting机制的影响;
- 分析重置频率和重置网络模块如何设计?
评论
- 考虑两个弱相关的分布函数(考虑用某种指标度量,例如互信息?),用其中一个函数作为目标,去训练另一个函数,拟合效果会很差吗?再用一个均匀分布去拟合呢?这似乎也是SimBa那篇工作的思想,模型保持拟合简单函数,那向其他函数迁移难度会更小。一种慢学习的原则。
- 如何衡量模型相对于任务,处于什么阶段,是初学者,专家,还是已经陷入恶性循环。
- 这些“过拟合”后重置网络参数的算法思路,很像决策树的剪枝操作,如果能够在一开始就识别到问题,避免反复重置参数,训练效率会更高。
- 资格迹能否缓解自举带来的问题。
- tradeoff——efficiency & effectiveness。回放率体现的就是这种权衡。
- 相较于重置参数,成比例衰减参数是什么结果?这可以起到缩小Q值尺度的效果,重新学习,并且缩小的是标签中自举要素的成分。