SimBa - Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
本文最后更新于:2025年2月21日 下午
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
原文:SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
在DRL领域,如何设计网络使其能够从扩展参数量获益,出发点依然是“如何将scaling law引入DRL”。
这篇文章提供了一个切入视角——simplicity bias(简单性偏好)。
基于这个视角,设计了SimBa网络结构。
实验验证了SimBa网络结构可以对多种RL算法,多种游戏场景提升算法表现。
前置知识
扩展神经网络规模是当今CV和NLP领域发展的一个关键驱动力。扩展模型参数一方面提升了模型的拟合能力,另一方面也增加了对训练数据的过拟合风险。
但事实上,这种神经网络倾向于朝简单的,泛化性好的函数收敛。这种现象被归因于神经网络本身具有的简单性偏好(simplicity bias)——优化算法和网络模块(例如随机梯度下降、ReLU、层归一化、残差模块等)引导高表达能力模型朝向简单,泛化性好的函数收敛。这些要素影响了神经网络在初始时刻表征函数的类型,而初始时刻表征函数越简单,网络越可能收敛到简单函数。
受这一现象的启发,文章思考如果放大这种简单性偏好,是否能够帮助在DRL领域实现模型参数的扩展?
这种简单性偏好,引导模型朝向更简单,泛化性更好的函数收敛。实际上放慢了网络的学习速度,慢慢拟合某种形状,不过早的形成一种复杂形状,有一种稳扎稳打的偏好。
定义1(函数复杂度):对函数进行离散傅里叶变换,利用傅里叶系数对频率进行加权求和——\(c(f)=\sum_{k=0}^{K}(\tilde{f}(k)\cdot k) / \sum_{k=0}^{K}\tilde{f}(k)\)。
\(k\)越大意味着频率越大。\(c(f)\)越大,函数高频成分越多,越复杂。反之亦然。
定义2(简单性偏好得分):\(s(f)\approx\mathbb{E}_{\theta\sim\Theta_{0}}[\frac{1}{c(f_{\theta})}]\)。其中\(\Theta_{0}\)是初始化网络参数的分布
由于不容易控制变量,论文比较的是不同网络结构初始化时刻的简单性偏好。有研究表明,网络训练期间收敛到的函数的复杂程度和网络初始化时刻的复杂程度强相关。
SimBa网络
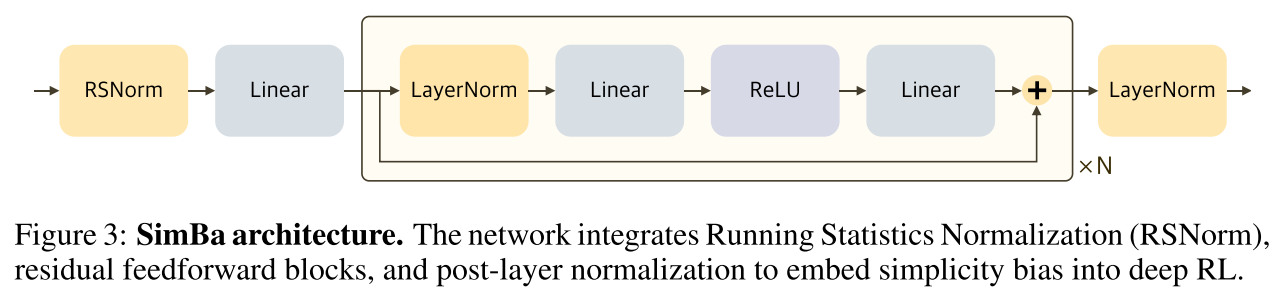
SimBa网络存在一条直接从输入到输出的线性的信息流通路径
输入归一化模块
设计理念:避免不成比例的大值特征主导学习过程。
这个模块更像是把监督学习的特征工程,数据清洗的任务,放到模型当中,本身没起到正则化的效果,后面实验也发现了这个模块相较于其他模块,没有为模型引入简单性偏好。
具体实现:1)计算特征的每个维度的running mean&variance;2)对特征的每个维度进行归一化。
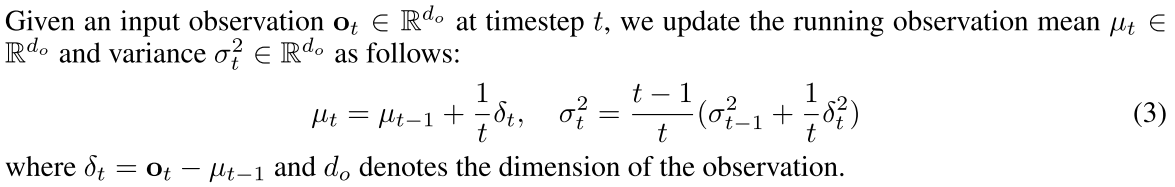

残差模块
设计理念:模型保持一种简单状态,除非必须要引入非线性。
具体实现:如图3所示。
层归一化模块
设计理念:确保激活值尺度一致。
是否在一定程度上缓解了另一篇文章提到的休眠神经元现象?
具体实现:如图3所示。
性能验证
实验检验两件事:1)SimBa是否增加了模型的简单性偏好;2)SimBa是否有助于模型扩展参数量。
简单性偏好分三步计算。1)从一个均匀分布中采样输入(\(\mathcal{X}=[-100,100]^2\subset\mathbb{R}^2\),划分为90000个点采样);2)计算网络输出;3)用这些输出计算傅里叶系数。
真实应用(测试)的任务,输入空间也在\(\mathcal{X}\)中吗?或者高度覆盖?否则函数在这片区域计算出的simplicity bias跟最终性能有何必然关联呢?
子模块分析
分析每个模块对增加模型简单性偏好的贡献,以及SimBa整体引入的简单性偏好。
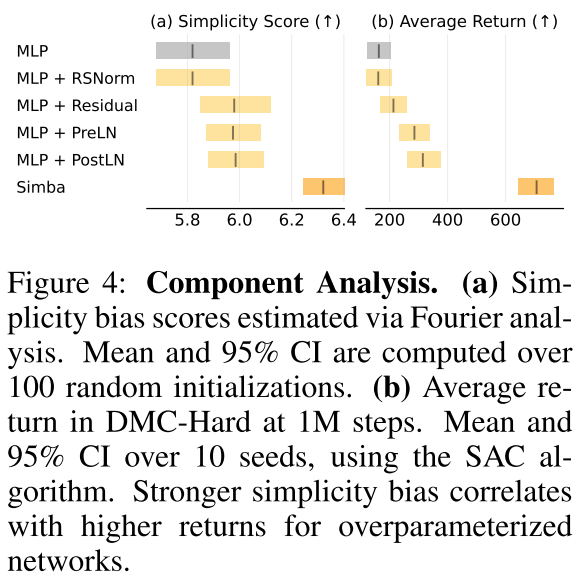
同其他网络结构对比
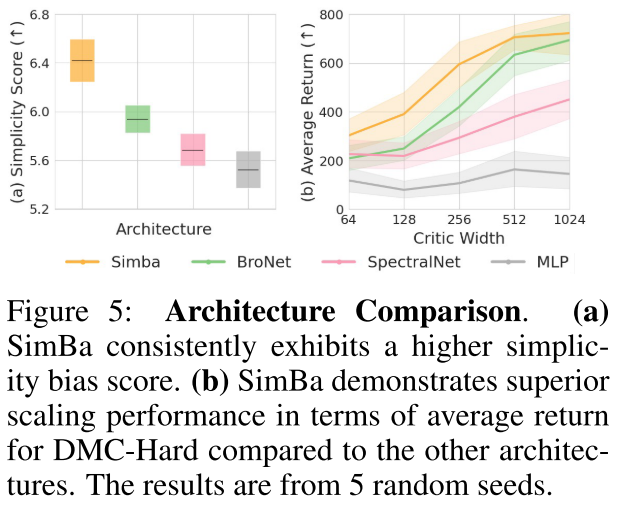
主要聚焦在扩展critic网络的隐层维度,因为扩展actor网络的隐层维度收益有限。
critic网络要同环境的多样性对应,观测越复杂,critic应当越复杂;
actor网络要同行为的多样性对应,行为越多样,actor应当越复杂
适用性验证
验证了SimBa网络在off-policy、on-policy和unsupervised场景下的适用性
消融实验
验证输入归一化模块的作用;
分析SAC算法,使用SimBa网络场景下,1)扩展actor网络和critic网络;2)扩展网络宽度的深度;对应的现象;
评估SimBa引入的简单性偏好,对回放率(训练时间)增加产生的消极影响的缓解作用。
评论
- 在RL中引入scaling law——增加模型参数量、增加梯度更新次数、增加训练时间
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!