The Dormant Neuron Phenomenon in Deep Reinforcement Learning
本文最后更新于:2025年2月19日 中午
The Dormant Neuron Phenomenon in Deep Reinforcement Learning
原文:The Dormant Neuron Phenomenon in Deep Reinforcement Learning
当前的训练技术,并不能够充分发挥网络的能力。
这篇工作介绍了DRL领域的一种现象——模型随着训练丧失拟合能力。
这同休眠神经元现象(dormant neuron phenomenon)存在相关性。
这篇工作揭示了这种现象在DRL领域普遍存在;分析了产生这种现象的可能原因;以及其造成的负面影响。
提出了ReDo算法缓解问题。
验证了ReDo算法的有效性;可以在提高回放率时,缓解产生的负面影响;可以在提高模型复杂度时,帮助模型更好的发挥潜力
这篇文章关注的是价值网络的问题(实验基于value-base算法)
前置知识
RL中引入DL,一方面提升了算法性能,但引入了新的训练问题。针对这些问题,一方面,改进RL算法(经验回放池,目标网络),另一方面,分析网络模型在RL场景下的特性。
监督学习中的“scaling law”表明模型表现和参数数量具有正相关性。在RL中,有证据表明,即使参数量足够的情况下,随着训练的进行,模型失去拟合能力,不能适应新的目标。
和监督学习相比,RL很重要的一点不同在于,网络训练过程的非平稳:1)输入数据非平稳。随着策略的演化,数据分布在变动;2)拟合目标非平稳。目标网络周期性更新。
这种非平稳叠加上自举,是否还能收敛到最优价值函数?本身TD算法就是有偏估计。
RL中价值函数的学习目标是分两部分的,一个是即时的reward,一个是自举的价值。
此外,基于函数估计的RL还要考虑一个问题,就是函数参数更新的耦合性,不同于基于表格的RL,函数参数更新会对其他状态的价值产生影响。
将DRL的价值函数估计同DL的回归任务做比较,DRL的价值函数是否更锐利。例如房价预测,特征的变化对回归值影响相对平滑,DRL的价值函数是否有这种特性,或者说,这是否就是不同游戏环境+reward设计的一般性区别?
定义1(休眠神经元):给定输入分布下,计算每个神经元的激活值的期望。然后,计算每层神经元期望激活值的平均数,每个神经元除以自己所在层的平均数得到休眠度

休眠神经元的定义是依赖于输入的分布的,在某个分布下休眠的神经元,在另一个分布下,未必还是休眠的,反之亦然。而输入分布随价值网络变动。
虽然给出了休眠神经元的定义,但在后续实验中,具体是如何计算的,输入的分布是如何取的,论文并没有提及。
定义2(休眠神经元现象):在训练过程中,休眠神经元的数量稳定上升。
实验分析休眠神经元现象
休眠神经元现象广泛存在
实验设置:DQN + Arcade Learning Environment
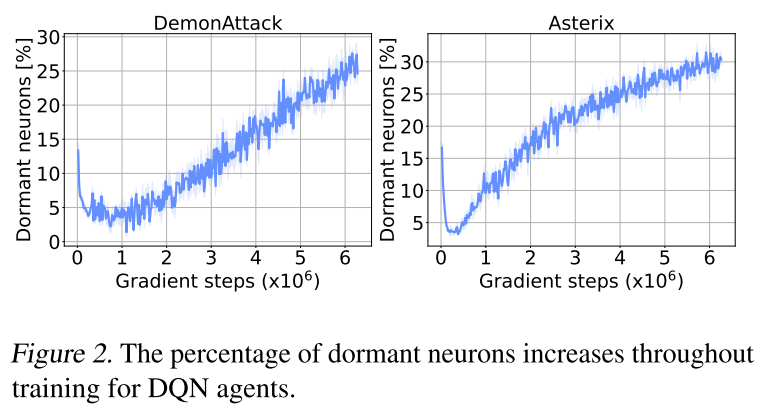
拟合目标非平稳加剧现象
实验设置:CIFAR-10任务,1)固定标签,训练一个卷积神经网络;2)每20个epoch打乱标签,训练一个卷积神经网络。
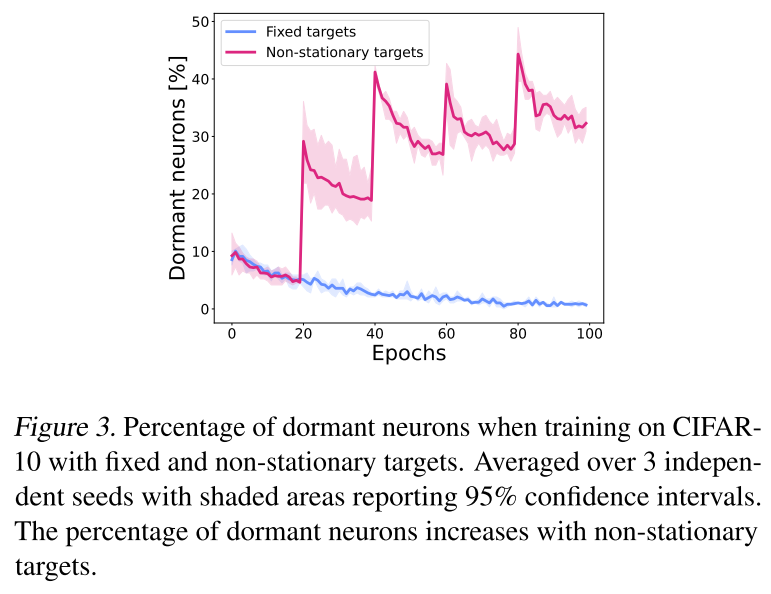
CIFAR-10是分类任务,RL中价值估计更接近回归任务,换一个回归任务分析更合理
输入数据非平稳不是主要原因
实验设置:离线RL(数据集固定) + DQN + Arcade Learning Environment
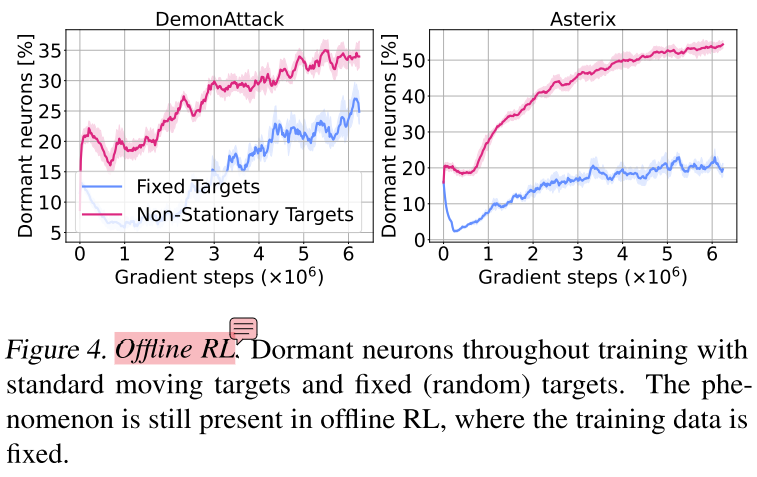
原文提到,为了分析这种设定下休眠神经元的来源,进行了fixed random targets实验(即将输入数据和拟合目标都固定,图中蓝色曲线),因为蓝色曲线休眠神经元更少,所以支撑了结论——拟合目标非平稳是休眠神经元现象的主要来源。但奇怪的是,蓝色曲线依然随训练过程上升,跟监督学习的下降趋势并不一致,也就是说,固定拟合目标后,还有其他原因,导致了神经元的休眠。
休眠神经元保持休眠
实验设置:DQN + Arcade Learning Environment
定义3(重叠系数):集合\(X\)和集合\(Y\)的重叠系数为\(overlap(X,Y)=\frac{|X \cap Y|}{\min(|X|,|Y|)}\)
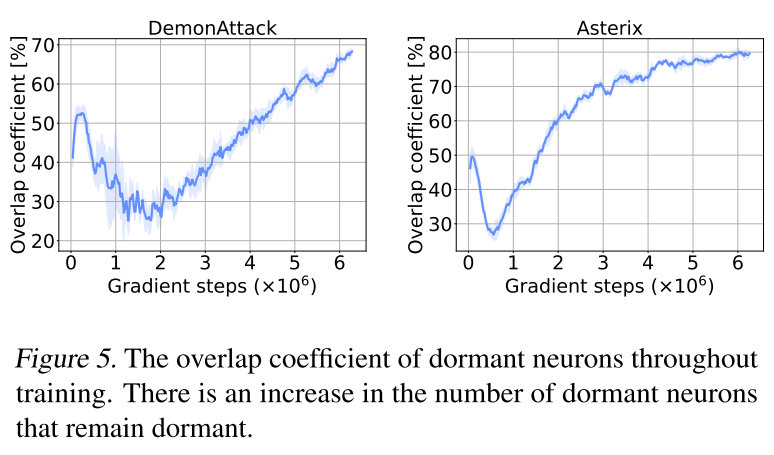
Figure 5 plots the overlap coefficient between the set of dormant neurons in the penultimate layer at the current iteration, and the historical set of dormant neurons.
作者认为图中的增长强力的支撑了结论——休眠神经元在训练的剩余时间内保持休眠。但图5中最高重叠率是80%,意味着还是有20%的休眠神经元能够通过训练,或输入数据分布的改变等原因重新激活。
频繁的梯度更新加剧现象
实验设置:DQN + Arcade Learning Environment
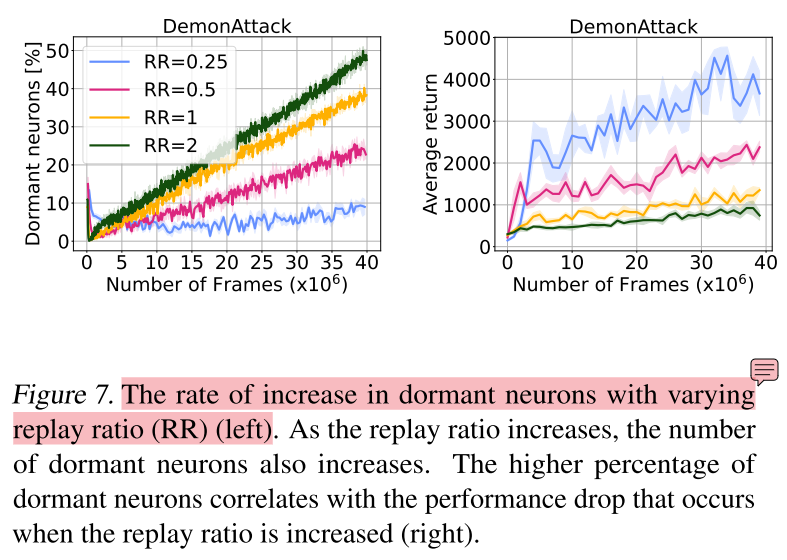
休眠神经元阻碍学习新任务
实验设置:在DemonAttack环境下,训练一个DQN智能体,设定RR=1,如图7所示,网络中存在很多休眠神经元,后续用“预训练网络”指代这个网络。然后找一个表现良好的DQN网络作为teacher网络,预训练网络作为student网络,进行知识蒸馏,同时用一个随机初始化的网络作为student网络也进行知识蒸馏。
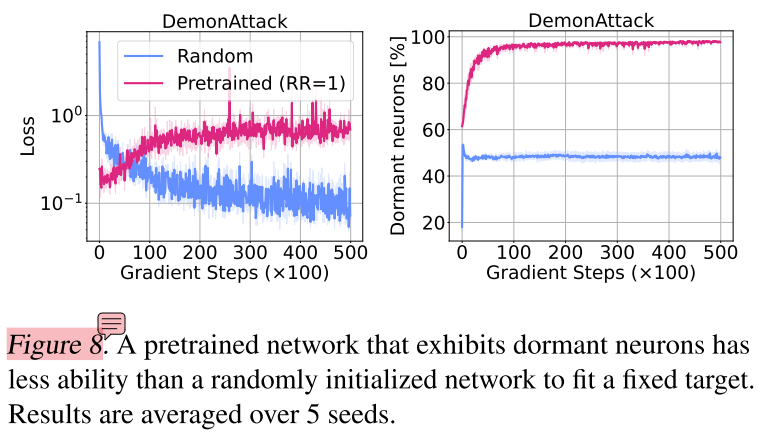
知识蒸馏的过程,输入数据的分布是什么?图8中预训练模型loss甚至在上升,难道不是应当先保证loss下降或保持不变,再进行现象分析?
知识蒸馏的过程,对于student网络来说本身就是一个监督学习,会什么还会出现休眠神经元比例的上升?
ReDo算法
算法介绍

算法的有效性
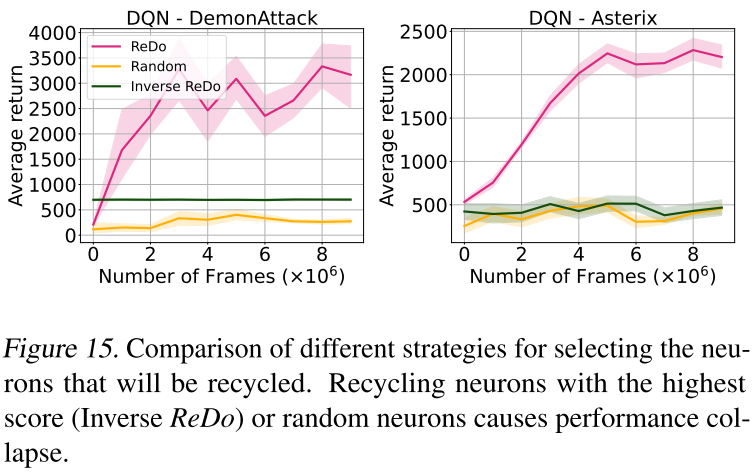
减少休眠神经元,提升智能体表现
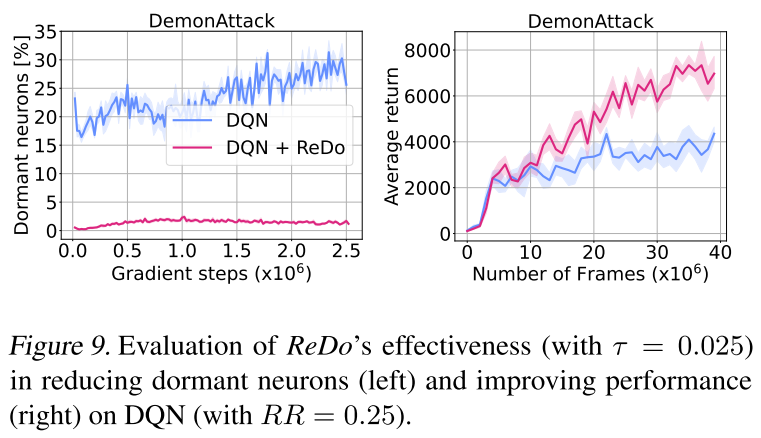
这个任务是否具有代表性?换一个游戏,实验结果还会是这样吗?
效果优于其他正则化方法
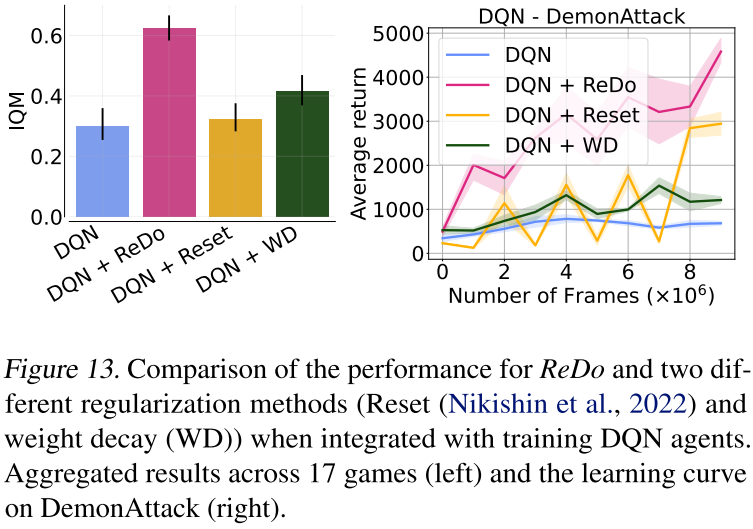
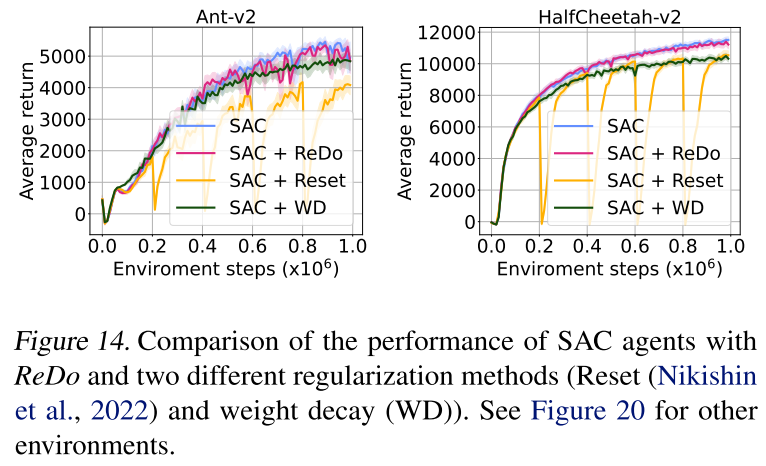
为什么在这种MuJoCo+SAC场景下,这些改进策略不再能够提升算法性能,难道休眠神经元在这类游戏场景中比较少?
缓解提高回放率产生的负面影响
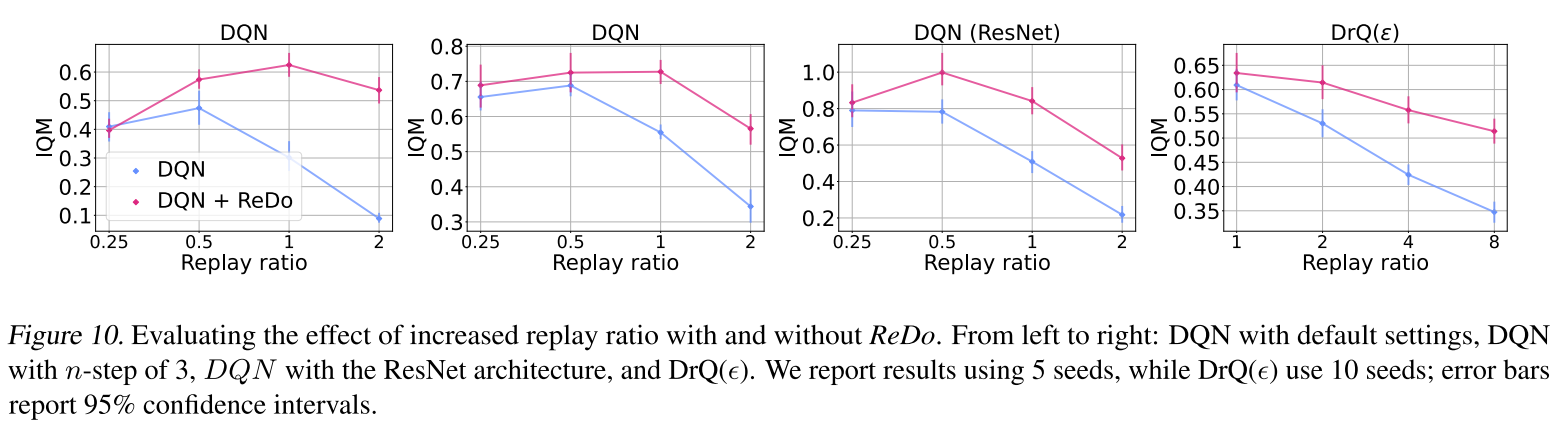
在多种场景(不同multi-step,不同网络结构,不同RL算法)下ReDo都能起到缓解,提高回放率产生的负面影响。
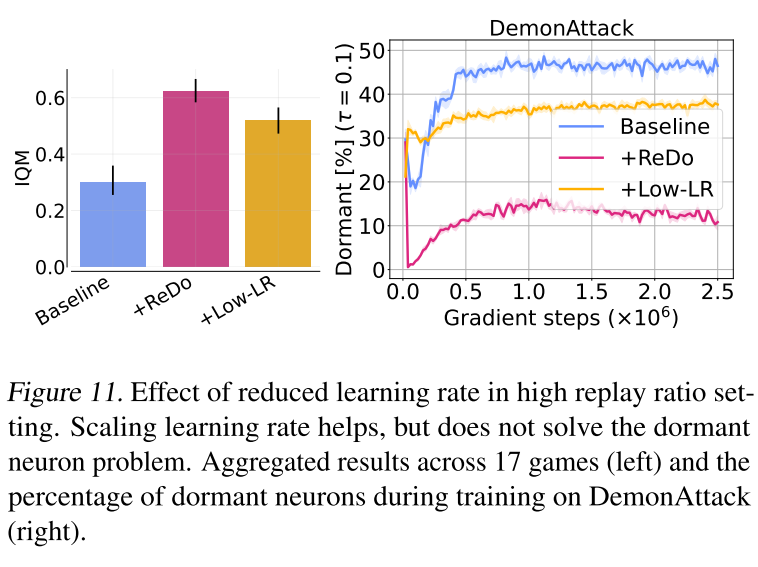
帮助模型更好的发挥潜力
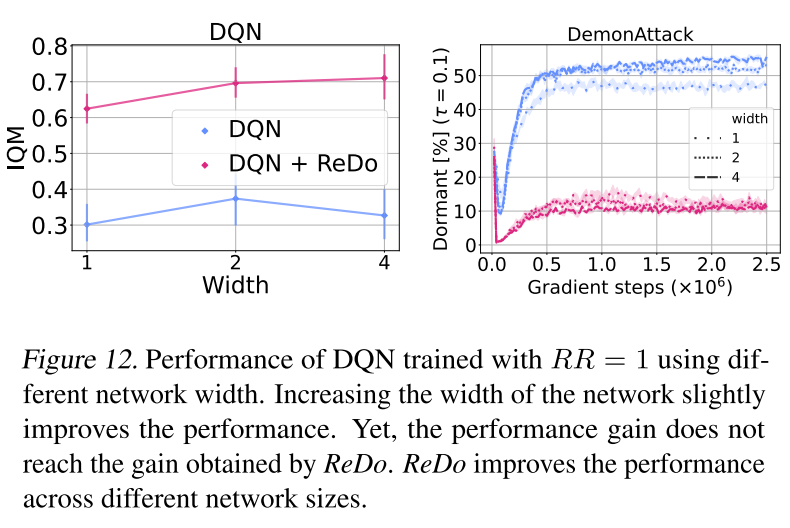
简单增加模型参数量,依靠传统训练,复杂模型的拟合能力发挥不出来;通过ReDo,休眠神经元的数量能够保持在一种较低的水平,增加模型参数量,算法表现还能得到一定程度提升。
不同模型宽度,休眠神经元的比例变化趋势非常接近,如何解释这个现象?
评论
有关神经元休眠的原因似乎还没调查清楚,文章针对问题打了个补丁,提升了算法性能。有进一步定位的空间。
问题不在于休眠神经元数量上升,而在于完美拟合该游戏的真实价值函数需要70%的神经元,却有50%的神经元陷入休眠,导致模型拟合能力发挥不出来。如果仅有30%神经元休眠,且模型表现优异,理论上应该是正常的,预示着过拟合。如果仅有20%神经元休眠,可能也意味着欠拟合。可以以高阶多项式拟合为例。
理论上在RL领域不存在监督学习的那种过拟合问题,因为给定了环境的模型(游戏本身),RL的数据可以无限生成,但是生成数据本身依赖于策略,RL因此有特有的问题——探索&利用。
可以做一个小测试。调整epsilon衰减的速率,观察休眠神经元变化的趋势是否会受影响?
可以测试一下蒙特卡洛方法是否还有休眠神经元现象,自举是否是一个重要因素。
相较于论文中经常出现的休眠神经元的比例,可以尝试去统计神经元激活值的分布,可能更有助于我们发现问题。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!